Les langues et le multilinguisme ont toujours été une partie importante des projets Wikimedia.
Le projet «Lingua Libre» vise à rendre les langues et leurs sons librement disponibles sous forme de métadonnées structurées. Jens Ohlig de Wikimedia Allemagne s’est entretenu avec Antoine Lamielle, développeur principal de Lingua Libre, à propos du projet et de son utilisation du logiciel Wikibase.
MediaWiki, le logiciel libre et open source de Wikipédia et de ses projets frères, est largement connu et utilisé en dehors de l’écosystème de Wikimedia, alimentant des milliers de wikis individuels à travers le monde.Moins de gens savent que Wikibase – le logiciel derrière Wikidata, la base de connaissances de Wikimedia – est également disponible en tant que logiciel libre et ouvert, et qu’il peut être utilisé pour des bases de données externes et des projets de données ouvertes.Pour souligner la manière dont les organisations utilisent Wikibase, la Wikimedia Foundation et Wikimedia Allemagne publient une série de billets de blog intitulée «Les multiples visages de Wikibase».
Les nombreux visages de Wikibase: Lingua Libre rend les \lɑ̃.ɡaʒ\ audibles
Les langues et le multilinguisme ont toujours été une partie importante des projets Wikimedia. Après tout, les projets Wikimedia sont disponibles dans près de 300 langues. Mais la plupart de ces langues ne sont accessibles en tant que sources de connaissances, que sous forme écrite. Lingua Libre a pour objectif de changer cela en rendant l‘oralité d’une langue et sa prononciation librement disponibles sous forme de donnée structurée.
Jens Ohlig a interviewé Antoine Lamielle, développeur principal de Lingua Libre, à propos de son projet et de l’utilisation de Wikibase.
Jens : Peux-tu te présenter ? Qu’est-ce qui t’a amené à participer aux projets Wikimedia ?
Une partie de l’équipe derrière Lingua Libre avec Antoine à gauche.
Antoine : Je suis 0x010C sur les projets, alias Antoine Lamielle et bénévole aux projets Wikimedia depuis 2014.
J’ai commencé à contribuer un peu par hasard, convaincu par la philosophie du libre partage des connaissances. Au fil du temps, je suis devenu un sysop et vérificateur de la Wikipédia en français, un contributeur de Wikimédia Commons, tout en travaillant sur de nombreux aspects techniques des wikis (maintenance et développement de robots, de gadgets, de modèles, de modules). Maintenant, je suis également l’architecte et le principal développeur de Lingua Libre depuis la mi-2017.
En dehors des projets, je suis un ingénieur logiciel français, passionné de kayak, de photographie et de linguistique.
Jens : Parle-nous de Lingua Libre ! Qu’est-ce que c’est ? Quelle est son histoire ? Quel est son statut en ce moment ?
Antoine : Lingua Libre est une bibliothèque d’enregistrements libres de prononciation audio que tout le monde peut compléter avec des mots, des proverbes, des phrases, etc. Ces sons enrichiront principalement les projets Wikimedia tels que Wikipedia ou le Wiktionnaire, mais aideront également les linguistes dans leurs travaux de recherches.
C’est un nouveau projet qui tire ses racines du projet français « Langues de France » , dont le but est de promouvoir et de préserver les langues régionales en danger sur les sites Wikimedia. Nous avons constaté à ce moment-là que seulement 3% de toutes les entrées du Wiktionnaire avaient un enregistrement audio. C’est vraiment dommage étant donné que c’est un élément très important ! Il permet à quiconque ne comprenant pas la notation API – soit une grande partie de la population mondiale – de savoir prononcer un mot. À partir de là, la première version de Lingua Libre est née, un outil en ligne pour enregistrer des listes de mots.
Aujourd’hui, c’est un processus entièrement automatisé qui vous permet d’enregistrer et de téléverser des prononciations sur Commons et de les réutiliser sur Wikidata et le Wiktionnaire. Nous pouvons maintenant faire jusqu’à 1 200 prononciations de mots par heure – alors qu’avant on ne pouvait en faire que 80 par heure via le processus manuel !
Enregistrement de mots en langue basque avec Lingua Libre par Xenophon75 CC-by-CA 4.0
Jens : Qu’est-ce qui vous a amené à travailler avec Wikibase ? Pourquoi est-ce un bon choix pour Lingua Libre ?
Antoine: La première version de Lingua Libre rassemblait des métadonnées pour chaque enregistrement audio, mais elles étaient stockées dans une base de données relationnelle traditionnelle, sans aucun moyen de les réutiliser. Nous voulions améliorer ces métadonnées en dormance en permettant à quiconque de les explorer librement. Mais nous souhaitions également améliorer la flexibilité de l’ajout de nouvelles métadonnées. Wikibase, associé à un point d’accèsSPARQL, nous a offert toutes ces possibilités, et tout cela dans un environnement bien connu des Wikimédiens ! Associé aux autres avantages de MediaWiki – l’historique des versions, pour n’en nommer qu’un – le choix était vite fait.
Dans notre instance Wikibase, nous stockons trois types d’éléments différents: les langues (y compris les dialectes) importées directement de Wikidata ; les locuteurs, incluant des informations linguistiques sur chaque personne effectuant un enregistrement (quel niveau il / elle a dans les langues qu’il / elle parle, et où ces langues ont été apprises, l’accent, etc.) ; et les enregistrements. Ces élements sont créés de manière transparente par l’enregistreur de Lingua Libre pour chaque enregistrement effectué, en liant le fichier sur Wikimedia Commons aux métadonnées (langue, transcription, date de l’enregistrement, auquel l’article de Wikipédia / entrée de Wiktionnaire / Wikidata correspondant, etc.), mais aussi à l’article de son auteur.
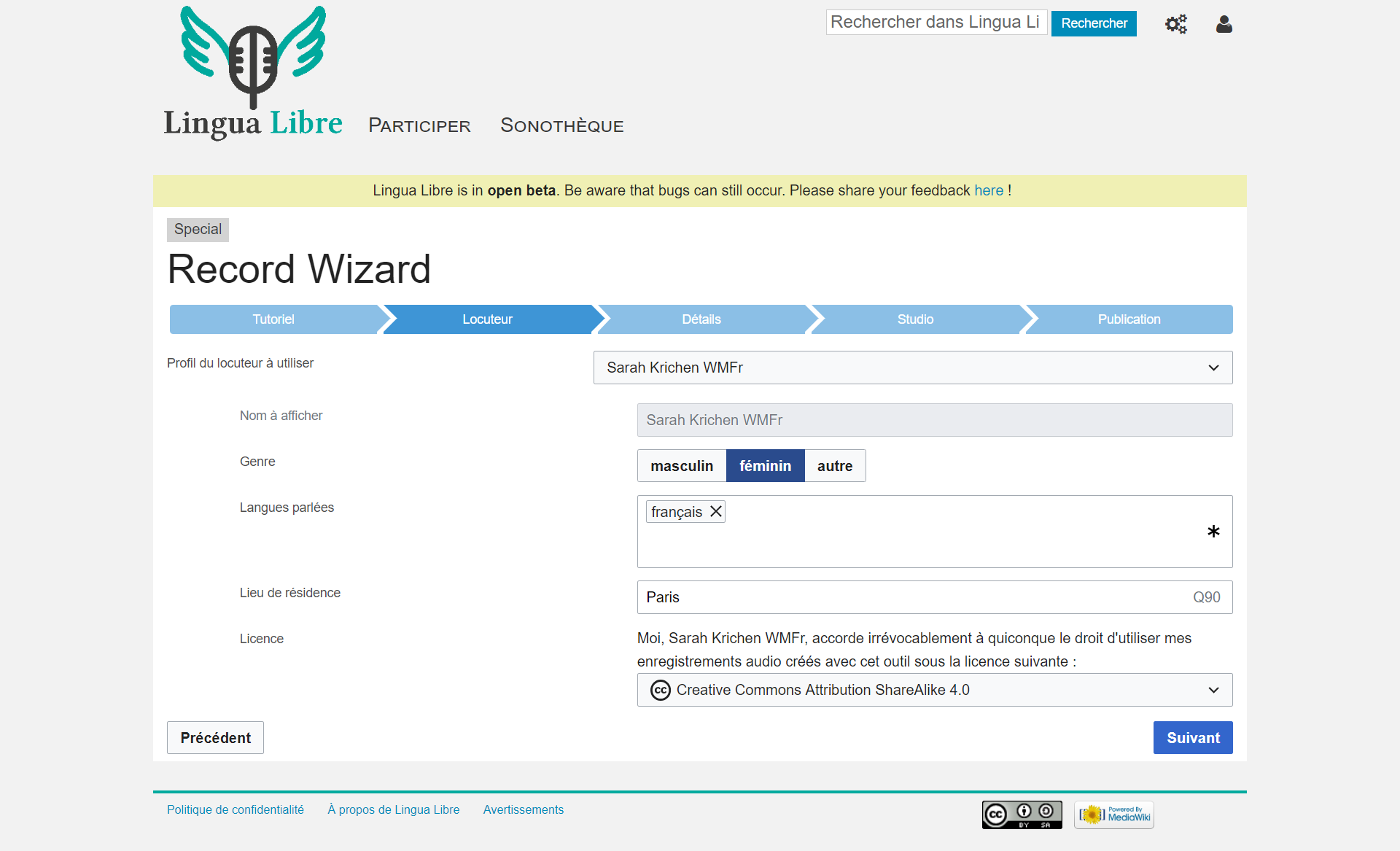
Aperçu d’un profil de locuteur de la plateforme Lingua Libre
Jens : Avez-vous découvert des choses positives sur le logiciel Wikibase ? Avez-vous rencontré des obstacles ? Y a-t-il des améliorations à apporter ?
Antoine : L’utilisation du même logiciel que celui de Wikidata nous a permis de créer facilement des ponts avec ce projet et de tirer parti de cette incroyable richesse de données structurées. Par exemple, pour permettre à nos locuteurs de décrire où ils ont appris une langue, nous utilisons directement les identifiants de Wikidata. Cela présente de nombreux avantages à l’usage. Ainsi, lorsque nous demandons à un nouveau locuteur où il a appris une langue, il dispose d’une totale liberté quant au niveau de précision qu’il souhaite indiquer (pays, région, ville, quartier ou école s’il le souhaite), le plus souvent avec des labels traduits dans sa langue.
En coulisses, nous pouvons ainsi mélanger et réutiliser les données de Wikidata et de Lingua Libre via des requêtes SPARQL (par exemple, pour rechercher tous les enregistrements effectués dans un pays ou pour pouvoir écouter les variations de prononciation du même mot dans plusieurs régions différentes) et tout cela sans avoir à gérer les coûts, les limitations et la maintenance que générerait une base de données géographiques !
Cependant, c’est actuellement plus un ensemble de manipulations qu’une solution parfaite. Les éléments Wikidata sont actuellement stockés en tant qu’identificateurs externes dans notre instance Wikibase, et l’ensemble de l’interface utilisateur / UX dépend des appels AJAX côté client vers l’API Wikidata. L’idéal serait de pouvoir fédérer plusieurs Wikibases, leur permettant de partager des éléments de manière native entre elles.
Texte publié initialement en allemand par Jens Ohlig pour Wikimedia Allemagne sous CC-BY-SA 3.0 le 14 décembre 2018.
 Faire un don
Faire un don Les nombreux visages de Wikibase: Lingua Libre rend les \lɑ̃.ɡaʒ\ audibles
Les nombreux visages de Wikibase: Lingua Libre rend les \lɑ̃.ɡaʒ\ audibles
.jpg)